Nvidia rivoluziona CUDA con il modello Tile per GPU Blackwell
CUDA 13.1 introduce il modello Tile per ottimizzare l'esecuzione tensoriale su GPU avanzate, aprendo nuove frontiere nell'elaborazione dati.
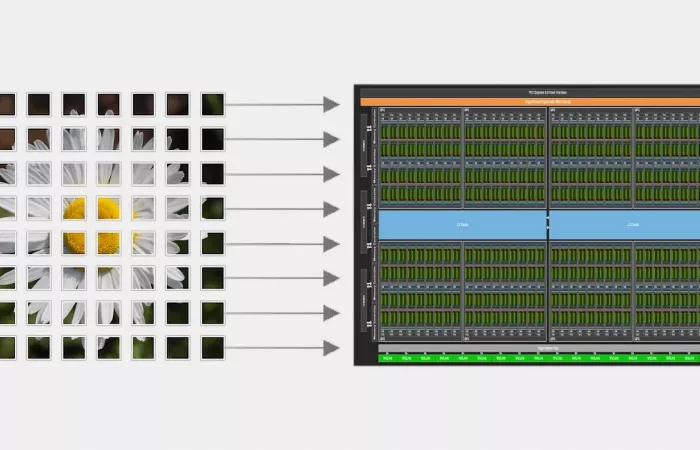
Nvidia ha rilasciato CUDA 13.1, segnando un cambiamento significativo nel suo software stack per GPU con l'introduzione del nuovo percorso di programmazione CUDA Tile. Questo aggiornamento innova il tradizionale modello di esecuzione single-instruction, multiple-thread (SIMT), orientandosi verso un'esecuzione focalizzata sui tensori, in linea con i processori di classe Blackwell e successivi.
Il modello CUDA Tile permette agli sviluppatori di descrivere le computazioni attraverso operazioni su blocchi strutturati di dati, come le sottomatrici, senza la necessità di specificare thread o ordini di esecuzione. Questo approccio sposta l'attenzione da come il calcolo viene eseguito sull'hardware a cosa deve essere calcolato, garantendo scalabilità delle prestazioni su diverse generazioni di GPU.
In particolare, CUDA Tile introduce CUDA Tile IR, un set di istruzioni virtuali che assicura stabilità a lungo termine per i calcoli basati su tile. Inoltre, il nuovo cuTile Python consente agli sviluppatori di scrivere kernel orientati ai tile direttamente in Python.
Questa evoluzione risponde alle esigenze di carichi di lavoro moderni, che richiedono sempre più operazioni tensoriali, riflettendo i cambiamenti architetturali negli acceleratori hardware di Nvidia. Con questo aggiornamento, Nvidia si prepara a supportare un ampio spettro di applicazioni, dalla IA alla simulazione scientifica, ottimizzando l'uso delle risorse hardware future.
Cos'è il modello di programmazione CUDA Tile introdotto in CUDA 13.1?
CUDA Tile è un nuovo modello di programmazione basato su tile che consente agli sviluppatori di descrivere le computazioni attraverso operazioni su blocchi strutturati di dati, come le sottomatrici, senza la necessità di specificare thread o ordini di esecuzione. Questo approccio semplifica la programmazione GPU e migliora la scalabilità delle prestazioni su diverse generazioni di GPU.
Quali sono i componenti principali introdotti con CUDA Tile?
CUDA Tile introduce due componenti principali: CUDA Tile IR, un set di istruzioni virtuali che assicura stabilità a lungo termine per i calcoli basati su tile, e cuTile Python, un linguaggio specifico per dominio che permette agli sviluppatori di scrivere kernel orientati ai tile direttamente in Python.
In che modo CUDA Tile migliora l'utilizzo delle Tensor Cores nelle GPU NVIDIA?
CUDA Tile astrae l'utilizzo delle Tensor Cores, permettendo agli sviluppatori di concentrarsi sugli algoritmi piuttosto che sui dettagli hardware. Questo approccio garantisce che il codice scritto con CUDA Tile sia compatibile con le attuali e future architetture di Tensor Core, facilitando l'adozione di nuove tecnologie senza modifiche significative al codice esistente.
Quali sono i vantaggi di utilizzare cuTile Python rispetto alla programmazione CUDA tradizionale?
cuTile Python offre un livello di astrazione più alto rispetto alla programmazione CUDA tradizionale, permettendo agli sviluppatori di scrivere kernel GPU utilizzando sintassi Python familiare. Questo semplifica lo sviluppo, riduce la complessità del codice e facilita l'integrazione con altri strumenti e librerie Python.
Come si confronta il modello di programmazione CUDA Tile con il modello SIMT tradizionale?
A differenza del modello SIMT
Quali sono le implicazioni di CUDA Tile per lo sviluppo di applicazioni di intelligenza artificiale?
CUDA Tile è particolarmente vantaggioso per le applicazioni di intelligenza artificiale, poiché molte di esse si basano su operazioni tensoriali. Il modello di programmazione basato su tile facilita l'implementazione efficiente di queste operazioni, migliorando le prestazioni e la scalabilità delle applicazioni AI su GPU NVIDIA.